Doreen R Bradley
Posts tagged with data analysis
Showing 1 - 10 of 19 items

Working with large-scale datasets to understand the effect of library resources on student success raises a number of concerns around individual privacy, data security, and analysis. This blog post, summarizing a recent article in College & Research Libraries, describes a recent grant-funded project at the University of Michigan, discusses the steps we took to address those concerns, and some of the lessons we learned.

In this interview, Dr. Adam Rountrey is the Research Museum Collection Manager (Vertebrates/Plants) and 3D Specialist at the University of Michigan Museum of Paleontology (UMMP) describes his research on hormone levels in woolly mammoth and African elephants tusks. Several CT scans of these specimens are available in Deep Blue Data.

In this interview, Yingxiao Zhang (PhD candidate in the Climate and Space Sciences department) describes why she decided to share the data set entitled "Simulated historical (1995-2014) and future (2081-2100) pollen emission using PECM2.0" in Deep Blue Data.
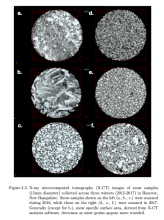
In this interview, Dr. Adam Schneider (U-M alum; PhD in Atmospheric, Oceanic and Space Sciences 2018) described why he decided to share the data set entitled "Supporting data for the Near-Infrared Emitting and Reflectance-Monitoring Dome" in Deep Blue Data.

In this interview, Nate Clemett (Master's student in the naval architecture and marine engineering department) describes his research and why he decided to share his data set entitled "Flywheel Energy Storage System Roll Dataset" in Deep Blue Data.
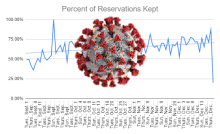
The interruption to library services caused by COVID-19 meant we needed to quickly develop new data collection strategies to give us information to manage our modified services for the 2020-2021 academic year. It also gave us an opportunity to conduct a deep reflection and assessment of how our regular collection had been going, and to be ready to make changes as we reinstituted more regular services. In two posts, we describe the evolution of our data collection efforts.
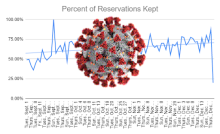
The interruption to library services caused by COVID-19 meant we needed to quickly develop new data collection strategies to give us information to manage our modified services for the 2020-2021 academic year. It also gave us an opportunity to conduct a deep reflection and assessment of how our regular collection had been going, and to be ready to make changes as we reinstituted more regular services. In two posts, we describe the evolution of our data collection efforts.
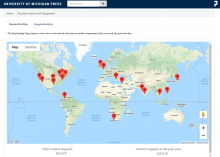
Between March 20 and August 31, 2020, the University of Michigan Press made all the titles in the Library-hosted ebook collection, UMP EBC, free-to-read. During this period, U-M Press staff gathered use data in the hope of assessing the impact of free-to-read content while informing the future business strategy. Three different assessment efforts are described in this post.
This blog post presents how the use of multiple streams of data benefited two recent U-M Library studies. For example, one recent study merged survey data, U-M human resources data, and Library document delivery data to provide a very rich picture of how diverse groups on campus use and experience the Library’s document delivery service. Some advantages of joining multiple data sources in assessment projects are discussed in the context of the two example studies.
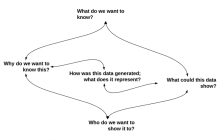
Chances are the work processes you already have in place are generating data that you could be using to learn more about those processes. In this second blog post, the author continues to highlight steps for working with data that is generated by your daily tasks.