In Web Archiving, do you get just the images or the entire site with most functionality intact?
Given the political climate, I was concerned about how long this site would be available, so I started with just getting the images/content and related text, thinking that would be the quickest option. Then, if there was an opportunity later, I thought I might be able to capture the content in context, essentially making a local copy of the website. The site in question, https://cultprotest.me/, as seen in Figure 1, does not work well with Archive-it because the images take a while to load from a database, as seen in Figure 2.
This blog will cover the process of just getting the image files and related text in Part 1. Part 2 will cover the process of making the JavaScript-enabled site function when run locally, allowing the content to have more meaning by being displayed in context.
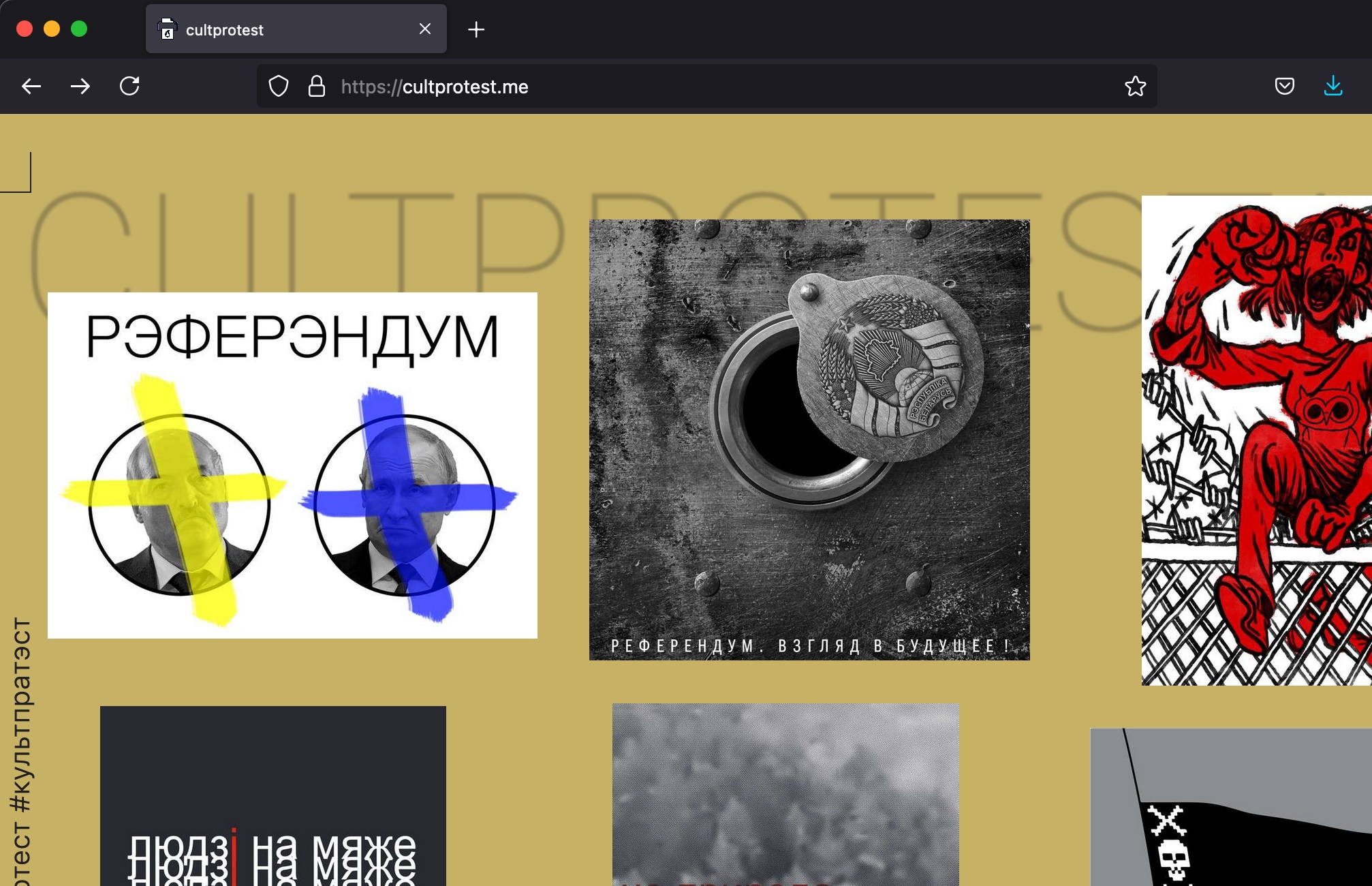
Figure 1 Frontend of cultprotest.me site
Part 1: Get the image files
- Get familiar with site
- Find tags for content
- Create a script for pulling content
- List files and text in CSV
I familiarized myself with the site by checking for the existence of robots.txt and then sitemap(s).xml; however, this site has neither. The next step/option is to view the page source.
In this case, “View Page Source” shows the code for a “stub” version of the site, just the background image, and “We're sorry, but cultprotest doesn't work properly without JavaScript enabled. Please enable it to continue.” (Figure 3) The issue is the site content is populated from a remote database.
Figure 2 cultprotest.me website loading...

Figure 3 Results of "View Page Source"
So, how do you capture the full HTML?
If this is a single site, i.e., scale is not an issue, you can use your browser’s Web Developer Tools to get the full HTML for the page for later parsing. For example, in the Firefox browser, the dev tools are in Tools > Browser Tools > Web Developer Tools. To copy the entire HTML to the clipboard, in the Inspector, right mouse click on the “<html “ tag to open the accessory menu, click on “Copy” then “Outer HTML,” Figure 4.
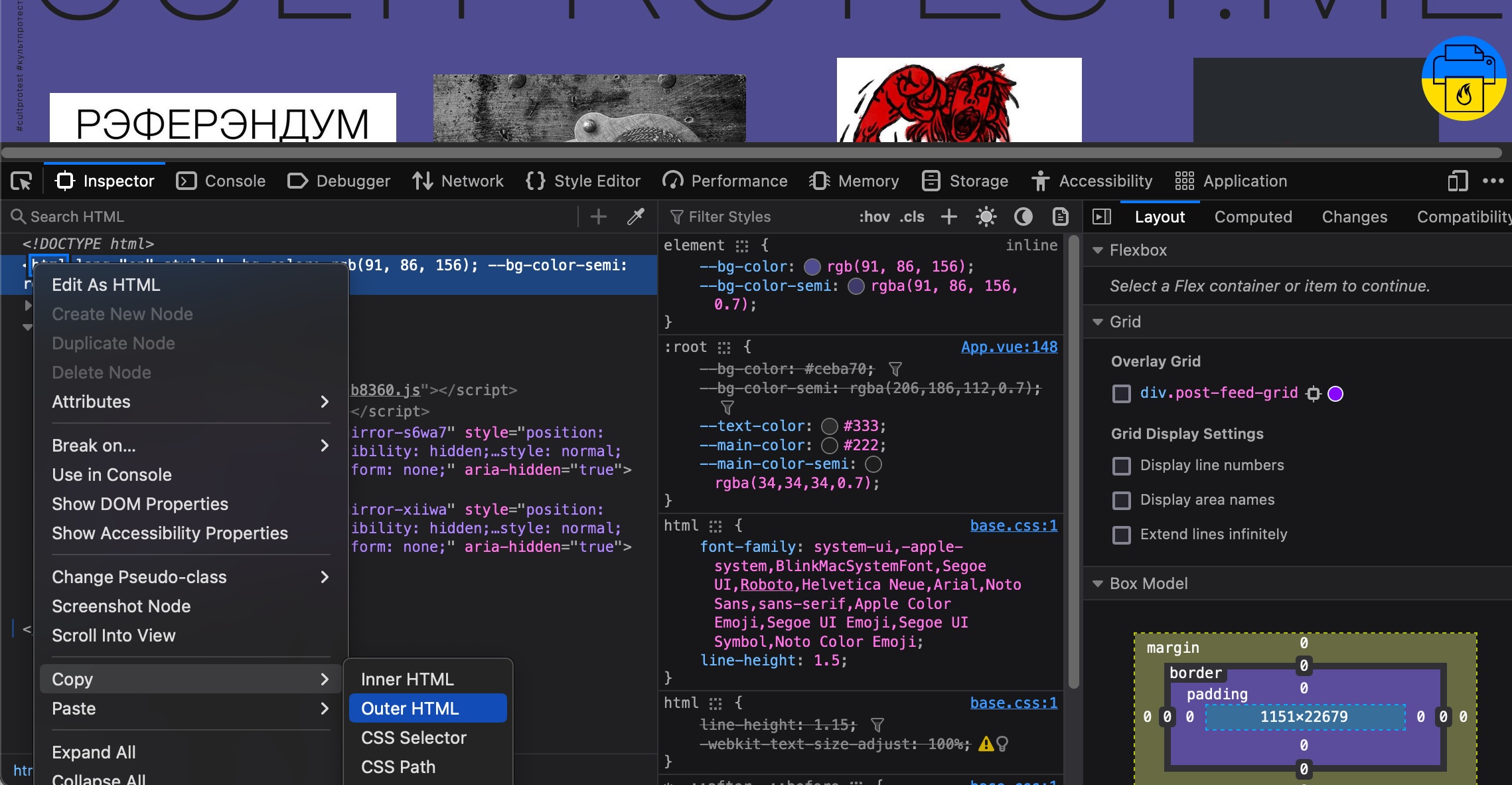
Figure 4 Copy Outer HTML
Open a text editor and save this as an *.html file.
You could also use the Selenium Python Library if you need to do this more programmatically (https://selenium-python.readthedocs.io/getting-started.html). This option will be discussed later in this blog (Example Selenium script: basicScrape.py)
Once the HTML has been saved, it’s helpful to go back into Web Developer Tools and use the element selector, Figure 5, to see what the code blocks look like for the content to be archived. In this case, we want the images and any alt-text to be captured.
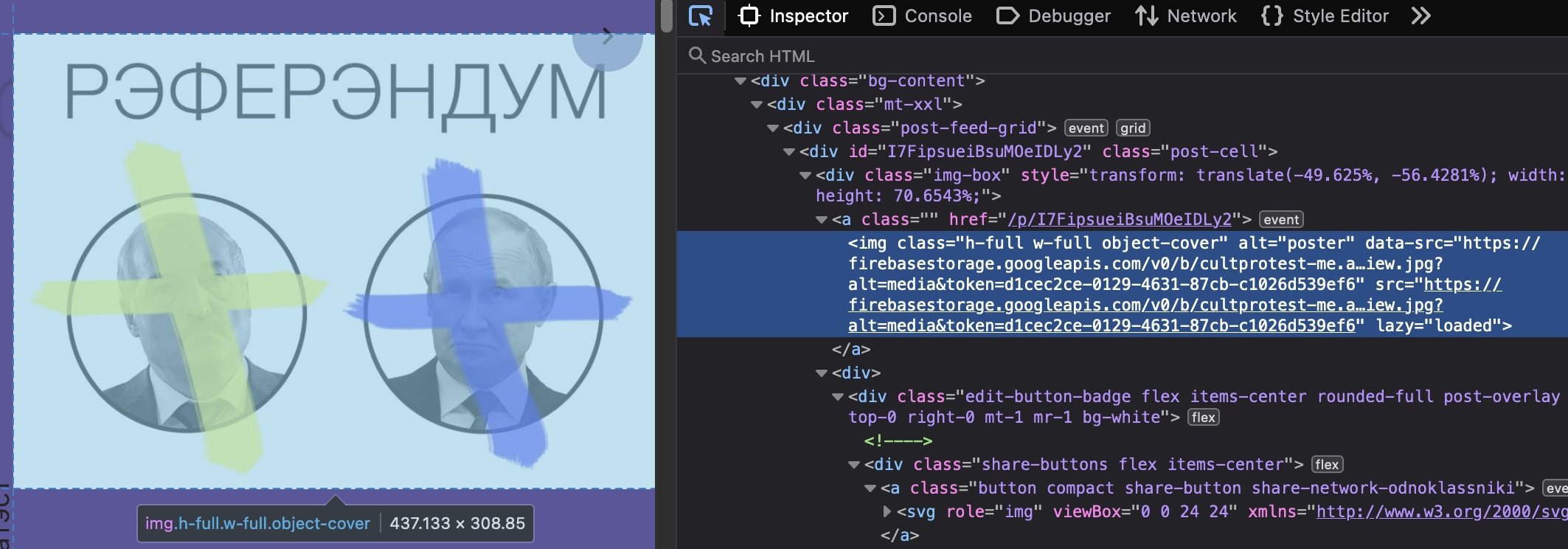
Figure 5 Image and data-src information for content
<div class="post-feed-grid"> – contains all the images
<img alt="poster" class="h-full w-full object-cover" data-src="cultprotestme_files/ImageFiles/TZsiSpjD20Vj6Zn2qzYslOUeKZ12%2Fs0bzpj330-hands-shadows-preview.jpg?alt=media&token=11a6b3a4-0eee-468d-b646-23a875b1bffc"
span[data-v-bee853a2=""]- alt-text information
In the ArtScrape.py script, I’ll use the Beautiful Soup Python library to loop over the “img” tags and get the URL from “data-src” within the “post-feed-grid” class.
From my brief review of the site, I saw two kinds of images: preview (this is a smaller version of the image that is displayed in a grid on the main page) and poster (which is the larger version that is accessed via the download button on each preview image).
Key parts of ArtScrape.py:
This statement narrows down where to look for the images:
imageDivs = soup.find_all("div", class_="post-cell")
This what part of each image “div” contains the URLs for the files:
previewUrl = image.find("img")["data-src"]
posterUrl = image.find("a", class_="download button compact")["href"]
Then, use regex to get just the file’s name from the URL:
posterPattern = '(appspot.com/o/)(.*\\.(jpg|png|gif|pdf))(\\?alt)'
previewPattern = '(appspot.com/o/)(.*\\.(jpg|png|gif|pdf))(.*\\ssrc)'
In this case:
TZsiSpjD20Vj6Zn2qzYslOUeKZ12%2Fs0bzpj330-hands-shadows-preview.jpg
ArtScrape.py runs on the index.html file, the *.html file copied earlier, to download all the image files and create a CSV with the list of files and any associated alt-text.
Once the image files are downloaded and the CSV file is created, I wanted to see if I could get this site working locally.
Part 2: Get all required files and run the site locally
- Get the index.html and all required scripts
- Create folder structure expected by index.html and site functionality
- Loop through all index.html files, looking for references to images
- Download images
- Run “find and replace” on all index.html files to point URL to local resources
- Configure Apache2 to handle encoded slashes to find images in folder structure
I want to be clear that I’m not a web developer or a JavaScript whiz of any sort, so I knew I needed to get as much of the original site code as possible. For this, I used “wget” to get the JavaScript and CSS files, as well as the “stub” index.html file:
wget -mpEk https://cultprotest.me/
The options used are: -mirror, -page-requisites, -adjust-extension, -convert-links
The great thing about wget is that it creates the folder structure the index.html expects to find. Unfortunately, it did not get image files.
The results of “wget”, Figure 6:
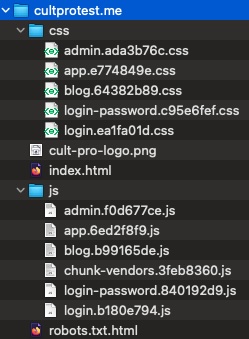
Figure 6 Folder structure created by running wget -mpEk
These CSS and JS files are all mentioned in the header of the index.html. Since wget only got the stub index.html, mentioned in Part 1, with no references to images, I had to find another way.
Because the images take time to load, you will want to slowly scroll to the bottom of the page before copying the HTML; otherwise, you will not capture the actual URL that points to the image files; you get this instead:
src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7"
The page requires a “real” URL for the image to be displayed:
src="https://firebasestorage.googleapis.com/v0/b/cultprotest-me.appspot.com/o/TZsiSpjD20Vj6Zn2qzYslOUeKZ12%2Fazaektm1-referendum-XX-22-A4-preview.jpg?alt=media&token=d1cec2ce-0129-4631-87cb-c1026d539ef6"
Finding a way to scroll slowly is where the seTest.py script comes in.
In seTest.py, I use “scrollBy” from the Selenium Python library to ensure images were all loaded:
driver.execute_script("window.scrollBy(0, 900)")
This statement allows you to programmatically scroll down the page 900 pixels at a time. This value needs to be adjusted to grab the last image when it gets to the bottom.
seTest.py gets the main index.html file, goes through the page, finds references to other pages, and opens each page. Once it opens the page, it captures the index.html, creates the local “/p/” folder structure, and saves the index.html files for each page referenced.
<a href="/p/ 0dmbSKWQZvX4AYDctubP "
New local file structure, Figure 7:
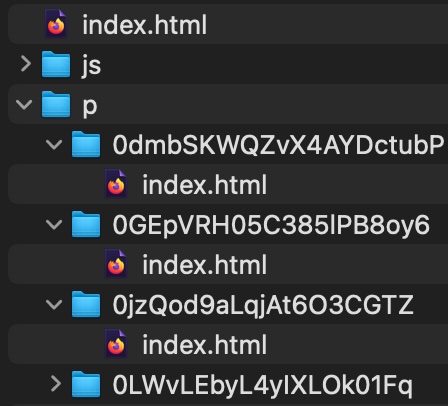
Figure 7 Folder structure of index.html files for overlay images
Now that the index.html files are all created, it's time to get the image files with NewScrape.py. It is an expanded version of ArtScrape.py.
One significant change from the original ArtScrape.py was the need to add “unquote” when processing the URL. I realized that Apache was looking for the file names with the Unicode characters rather than the percent-encoded characters I downloaded in Part 1.
unquote(url) #unquote helps with percent-encoded characters
For example, unquote changes this from the file name from index.html:
b84orwj8-Dlya-teh%2C-kto-ustal-molchat%D1%8C-x-preview.jpg
To this:
b84orwj8-Dlya-teh,-kto-ustal-molchatь-x-preview.jpg
Notice “%D1%8C” becomes the unicode character “ь.”
Unquote also allows the %2F in the URL to be converted to a “/,” creating a folder structure for the image files.
TZsiSpjD20Vj6Zn2qzYslOUeKZ12%2Fazaektm1-referendum-XX-22-A4-preview.jpg?
Without this, Apache may not be able to locate the files because it is expecting this folder structure, Figure 8, and file names with Unicode characters:
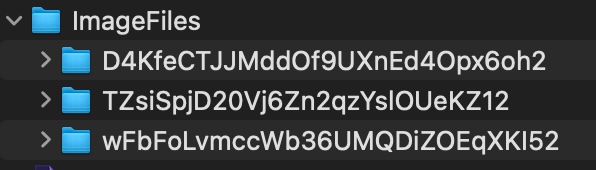
Figure 8 New image file parent folder structure created by using unquote to process the URLs
I say may here because it depends on your settings in the Apache config file (httpd.conf on MacOS. I experimented with various options for “--- AllowEncodedSlashes,” as mentioned in StackOverflow and the Apache documentation. I used “unquote” to create the folders and “--- AllowEncodedSlashes On.” This way, I didn’t have to change the URLs in the index.html files to match.
This regex statement is used to extract just the file name:
"(appspot.com/o/)(.*)(\\?alt)"
Something else I didn’t realize until this new process of trying to get the images to display locally is that I was missing a whole class of images:
class="post-overlay sticker"
There are not a lot of these sticker files, but if they are omitted, you get errors as shown below in the Web Developer Tools window, Figure 9:
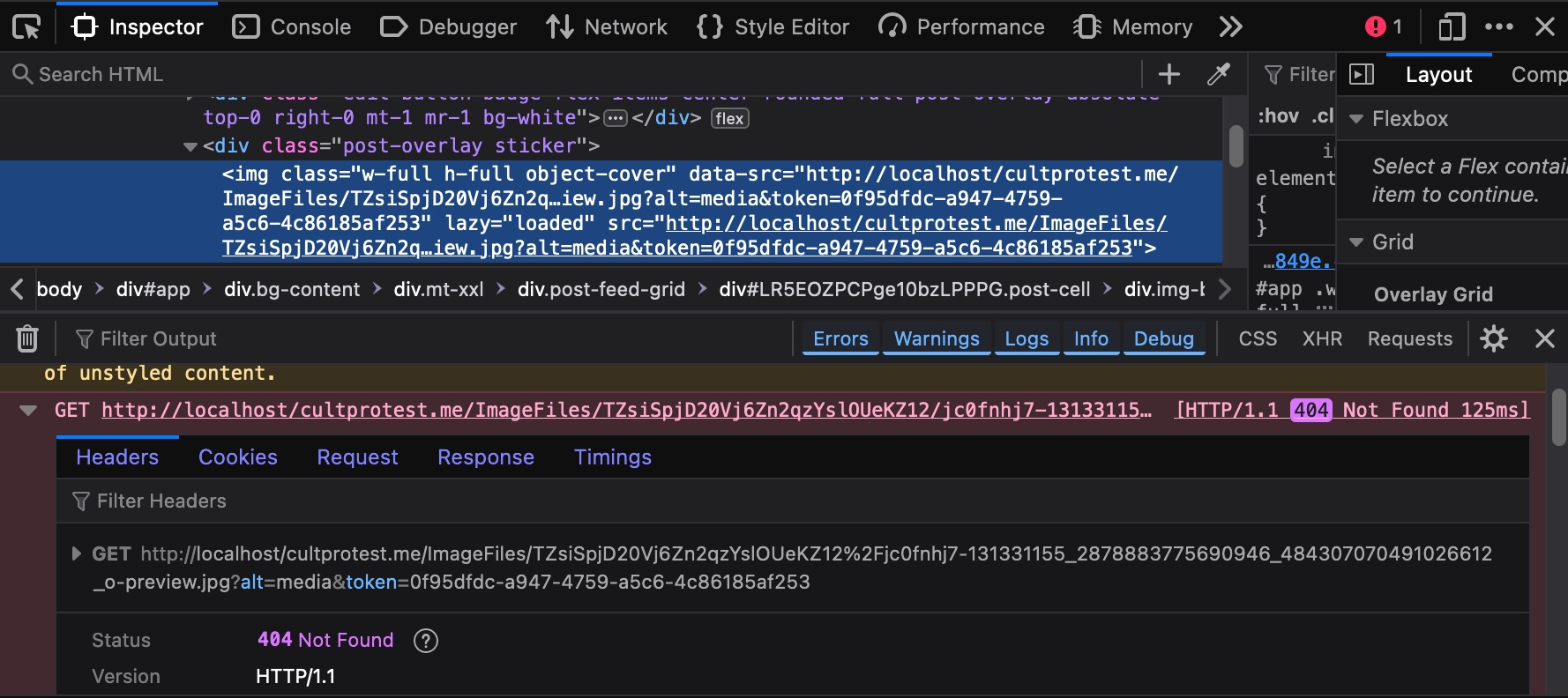
Figure 9 HTTP/1.1 404 Not Found error message shown in Web Developer Tools
I also noticed when trying to run this locally that some of the images displayed after clicking on the preview image were not captured during my first pass at downloading the image files; I so had to add some code to look specifically at the index.html files in the “/p/” folder. To eliminate duplicate file downloads, I checked for the existence of the filepath:
if os.path.isfile(filepath):
#print("File exists")
return filepath
pass
else:
#print("does not exist")
output_file = Path("../ImageFiles/" + fileLoc)
Now, with the image files downloaded to the ImageFiles folder, the last step is to modify all the index.html files to point to the assets locally using the script findReplace.py
This script uses Beautiful Soup again to parse the HTML; this allows me to narrow down modifications to just the <head> and <body> of the file:
hd = soup.head
bd = soup.body
For example, this finds the links to the CSS and JavaScript files in the header and prepends the links with "http://localhost/cultprotest.me."
target = hd.find_all("link")
for v in target:
newURL = "http://localhost/cultprotest.me" + v["href"]
v["href"] = v["href"].replace(v["href"], newURL)
So instead of this:
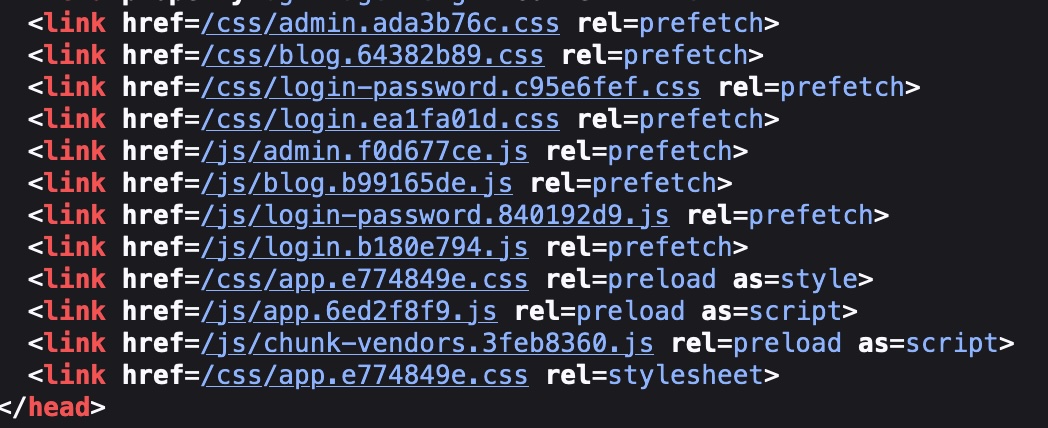
Figure 10 Index.html header showing relative references to JS and CSS files
We see this:
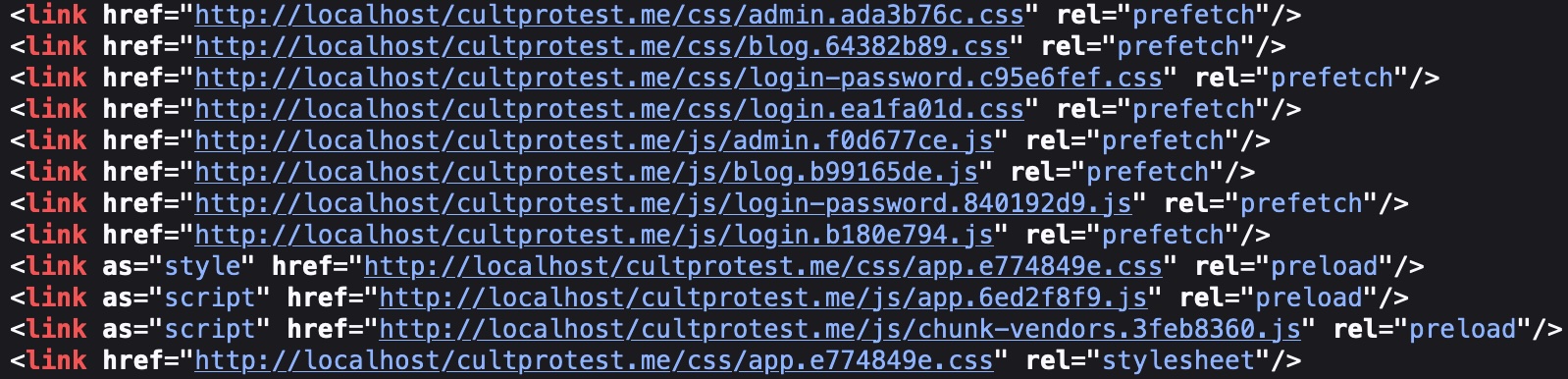
Figure 11 Index.html header absolute paths to JS and CSS files
Otherwise, Apache can’t find the CSS and JavaScript files.
Also, the most important update is to the “src” URLs, as mentioned earlier. Without capturing the full URL using the slow scroll, I wouldn’t have been able to do a simple find and replace to get these preview images to display:
image["src"] = image["src"].replace(
"https://firebasestorage.googleapis.com/v0/b/cultprotest-me.appspot.com/o/",
"http://localhost/cultprotest.me/ImageFiles/")
Lastly, using this script, I could “comment out” a couple of script references at the bottom of the index.html files, which caused errors that I couldn’t resolve in another way. Using soup.replace did the trick:
soup = str(soup).replace('<script src="/js/chunk-vendors.3feb8360.js"></script>',
'<!--script src="/js/chunk-vendors.3feb8360.js"></script-->')
soup = str(soup).replace('<script src="/js/app.6ed2f8f9.js"></script>',
'<!--script src="/js/app.6ed2f8f9.js"></script-->')
Once all three of the scripts have been run in order, seTest.py, NewScrape.py, and findReplace.py after the initial wget, you have this cultprotest.me running at http://localhost/cultprotest.me/, looking like this, Figure 12 and Figure 13:
Figure 12 Frontend of localhost/cultprotest.me/
Figure 13 Image overlay of http://localhost/cultprotest.me/p/I7FipsueiBsuMOeIDLy2/
Was all this worth it? I’m not sure yet. Presumably, this site content will change so I will have to make a script to look for updates and whatnot. I can zip the top-level cultprostest.me folder, and it will contain everything someone needs to see this site as it was in Fall 2024 if they have a means of running a local web server. If not, then they will have all the images and related text. I’m not sure how scalable this is, but now I have a process and some scripts if I come across a similar site in the future. There is a much more complicated site using a similar setup, https://kalektar.org/k, so I may try to see if I can get that one running locally as well.