Machine learning is changing the world around us and it will continue to dramatically shape our future. Complex computer algorithms are slowly starting to define our interactions with vehicles, social media, and Netflix. That’s right, even the shows Netflix recommends for you are, in part, the result of a complex machine learning algorithm.
Despite the omnipresence of machine learning in the world around us, the mystique that surrounds these two words is palpable. Many people forfeit trying to understand how machine learning works upon reading the word algorithm. I, however, decided to delve into the topic through an online course. In an attempt to better understand just what is happening during a machine learning program, I completed the Lynda.com course, “Machine Learning and AI Foundations: Value Estimations,” taught by Adam Geitgey. Participating in the course left me believing that, although machine learning is a highly complex process, one does not need to understand exactly what is going on under the hood of the algorithm, so long as they can navigate the program. The adaptability of online learning is great; it allowed me to take the plunge into studying machine learning at my own pace. Machine learning is complicated, so the ability to pause or rewind a video allowed me to better understand the content. Geitgey decided to teach this class around the subject of predicting housing sale prices. In the course description, Geitgey validates this subject matter by remarking, “Value estimation [is] one of the most common types of machine learning algorithms.” I found this valuation content to be equally interesting and digestible. Value estimation is something that is often taught in statistics. I found it interesting to compare and contrast how the machine learning model worked with the data in contrast to traditional statistical approaches.
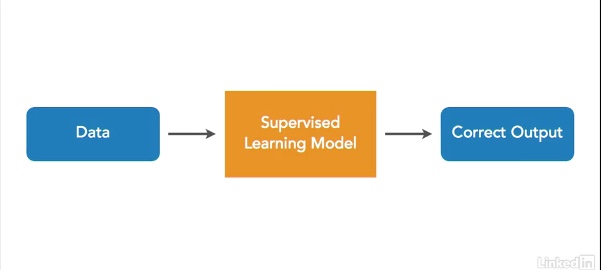
The class began by defining machine learning as, “computer algorithms that have the ability to learn without being explicitly programmed.” Geitgey explains that some computer algorithms can be very work-intensive and machine learning can step in to improve workflow in these instances. It may also help programmers solve problems that would be prohibitively difficult to solve using traditional programming framework. He frames the valuation program as usable by a real estate agent with a booming business, who no longer has time to evaluate the homes they are trying to sell. While this might be a stretch in the real world, companies like Zillow employ machine learning to accomplish similar tasks at larger scale. Building the course’s housing valuation program relies on supervised learning. The course explains supervised learning as, “The branch of machine learning where the computer learns how to perform a function by looking at labeled training data.” In our valuation program, we want our program to process a bunch of data about a house’s characteristics and then produce a single value estimation of what the house is worth. We will enable the program to “learn” by giving the computer a training set of data to learn how housing valuation works, and what housing characteristics are or are not important in valuation.
When building this supervised machine learning model, one of the first tasks we need to handle is determining the weight that each characteristic of a house should have on the final value estimation. There are a few components in this process, but arguably the most important is gradient descent. Using this process, you can determine the optimal weights for the data set without doing much math at all. This process is key in finding the weights that will allow your machine learning model to run properly.
Now comes the fun part of building the program, but in all honesty, you are not going to build too much from scratch. You will rely on libraries like NumPy, scikit-learn, and Pandas to do much of the heavy lifting for you. These are machine learning libraries that have been created by others and are open for you to use. You will load your data into the program, and then you will clean it up using feature engineering to ensure that the data set is optimized for the machine learning algorithm. Feature engineering will ensure that you are only using the factors that most influence what a home’s price is likely to be. If given the option, you always want more data so long as it is feasible. The model will learn better from a larger data set. Wanting more data does not mean that you want more features. More rows of data will help the model produce more accurate results, but more features will run into the curse of dimensionality. The curse of dimensionality is the point at which the amount of features is so large that the model will need exponentially more data for each added. This becomes untenable and your program will not be able to work.
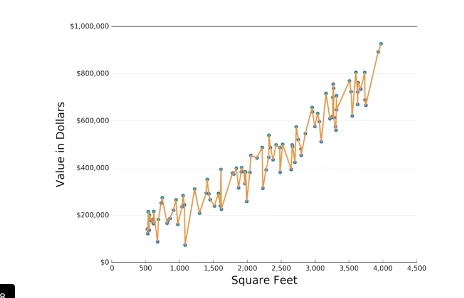
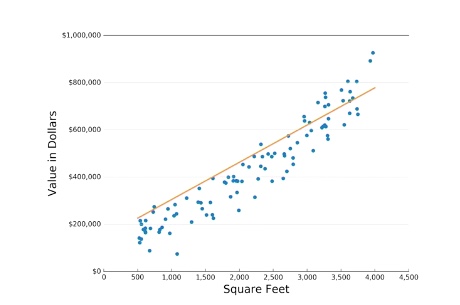
A major concern you will need to keep in mind while building a machine learning program is whether your model fits the data well. You may run into issues around overfitting or underfitting. Overfitting is when the model doesn’t actually make predictions, rather it is just remembering the data. You can think of overfitting as the graph located on the left below. Underfitting is the opposite of this problem and occurs when the program is not making precise predictions, most likely because the program is not complex enough for the data. You can picture this as the graph located below on the right. We want our model to exhibit a good fit, which is difficult to visualize. You will know that your data has good fit when the training set and test set errors are low.
While machine learning is complicated, resources like this course exist, which make it more accessible. The points outlined above may seem basic, but they are key concepts in understanding a machine learning program. I am not going to delve further into the specifics of building the valuations program. I suggest that if you want more detailed information, you should take the course. It walks you through building a machine learning model step-by-step, while always emphasizing the overarching themes. Ultimately, the course illustrates that understanding how to structure data and incorporate it into an already existing machine learning algorithm will open countless doors into the machine learning world.