In our inaugural Digital Collections Connection meeting on March 7, 2024, we shared a couple of slides that showcase the history of the technical infrastructure for digital collections at U-M Library. During the session, we heard that this overview of our systems was helpful to content partners in understanding current functionality and limitations. We wanted to take this opportunity to share the diagrams more widely and to provide more context and historical information about the origins of, and recent changes to, our digital collections platform.
What we had prior to 2022
The following diagram shows the technical ecosystem of our digital collections at U-M Library prior to 2022. The letters below correspond to labels in the diagram.
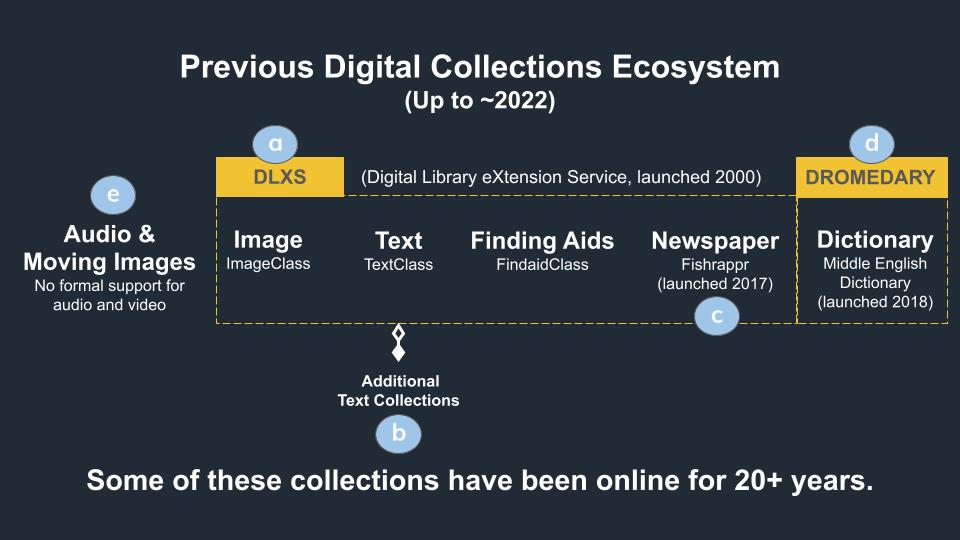
Diagram of the elements making up our digital collections ecosystem up until 2022.
a) Our core work has been in providing curated digital collections for research and instruction that contain digitized text and images. In addition, we are responsible for maintaining and hosting our online Encoded Archival Descriptions (EADs), i.e., online finding aids, for our partner archives. The technical infrastructure for these - Digital Library eXtension Service (DLXS) ImageClass, TextClass, and FindaidClass - was created over 20 years ago and we are still running and maintaining that system.
b) Prior to DLXS, we used older technical infrastructure (also still being maintained) to host around 20 other text-based digital collections. Some of our currently most popular digital collections reside on this infrastructure.
Examples: The Koran, Bible in English.
c) In 2017, we built a newspaper-specific application that allowed us to leverage part of DLXS to host our campus student newspaper, The Michigan Daily Digital Archives. We dubbed this technology fishrappr. Two more newspapers (The Michigan Citizen Digital Archives and The Detroit Jewish News Digital Archives) joined the platform soon after.
d) Around the same time, we received an NEH grant that, in part, allowed us to spend resources towards building a separate online application (called dromedary) for the Middle English Dictionary, a product with a long history at the University of Michigan. Prior to this, the dictionary was in the older technical infrastructure for hosting text-based digital collections.
e) Note that at this time, we did not have formal support for digitized audio and video (audio / moving images (AMI)) collections, which meant that we did not have a dedicated embedded viewer for these types of materials in our digital collections interface.
What we have now (as of January 2024)
The following diagram shows the technical ecosystem of our digital collections after extensive work to upgrade and improve our systems between summer 2022 and January 2024.

Diagram of the elements making up our digital collections ecosystem as of January 2024.
f) For our digitized text and image digital collections, we have done a major “uplift” of the interfaces, improving navigability, increasing consistency in the user experience, and providing a standardized viewer called Mirador for both text and image formats (May 2025 update - this is now an implementation with a customized viewer). In addition, we are now in compliance with university policy, i.e., Electronic and Information Technology Accessibility, and we are now usable on mobile devices (and our analytics show that many people access us on those hand-held devices!). You can read more about the planning for that work. The new interface for our image digital collections was launched in August 2022, and the large majority of our text digital collections in January 2024.
Examples: Chinese Papercuts (image digital collection), Making of America (text digital collection).
g) We had long desired a better system for finding aids that would allow users to discover EADs across repositories and collections, as well as to narrow their results by certain facets such as genre or time period. We also wanted end-users to find any digitized content available in our text and image digital collections directly from the finding aids. And we wanted to improve the interface for the same reasons noted above for text and image digital collections. We chose ArcLight as our platform, and launched our U-M Library Finding Aids application in April 2023. You can read more about what went into that work.
h) Around the same time, we chose an embedded AMI viewer called AblePlayer that is standards-compliant and allows good navigation for playing the media in addition to viewing captions and transcriptions simultaneously. We launched our first AMI digital collection, Hazen Schumacher's Jazz Revisited Radio Show, in May 2023. (Please note that a portion of this digital collection is accessible to the U-M community only, and the remainder is accessible by permission of the Music Library.)
At this point, we have improved interfaces, and in some cases built entirely new applications, for 83% of our digital collections!
A Quick Interface Comparison
Above we mentioned the interface “uplift” for image and text digital collections that reside in DLXS. Here are some comparison images to show this transformation.
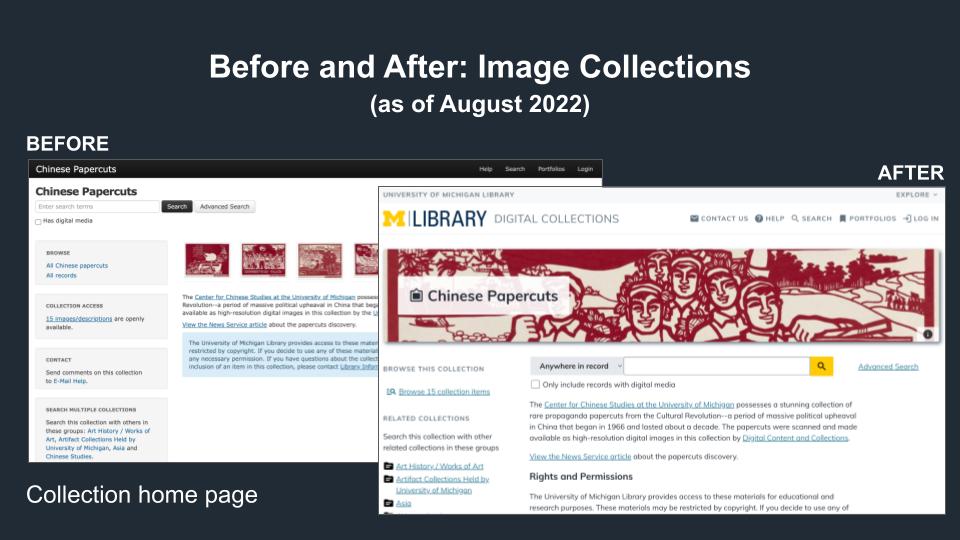
Before and After Image Collections home page
This side-by-side comparison showcases the original homepage for image digital collections (on the left) and the new homepage (on the right), which is fully accessible, easier to navigate and includes a more robust header and menu bar that is in keeping with our U-M Library Design System.
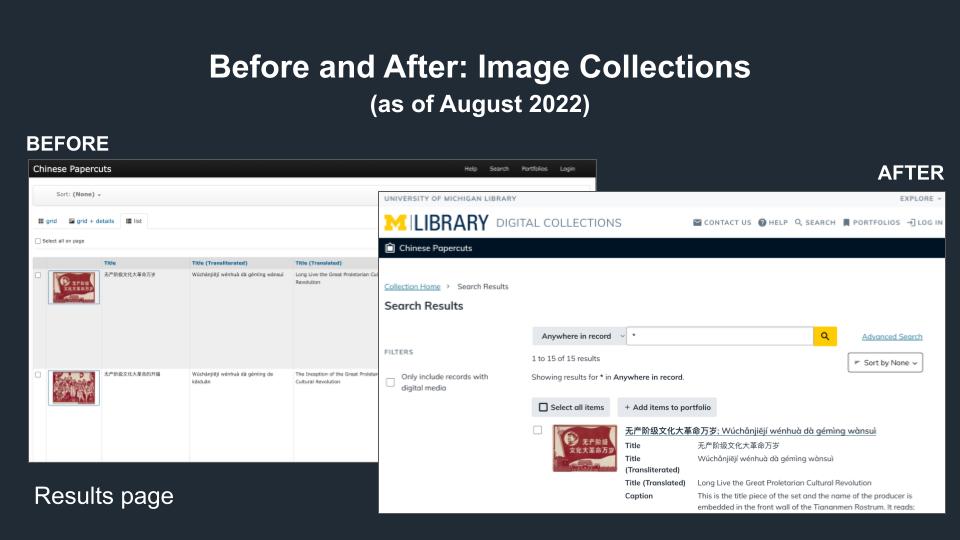
Before and After Image Collections results page
This comparison features the original results page for image digital collections (on the left) and the new results page (on the right), which removes the use of tables and other not-easily-navigable elements.
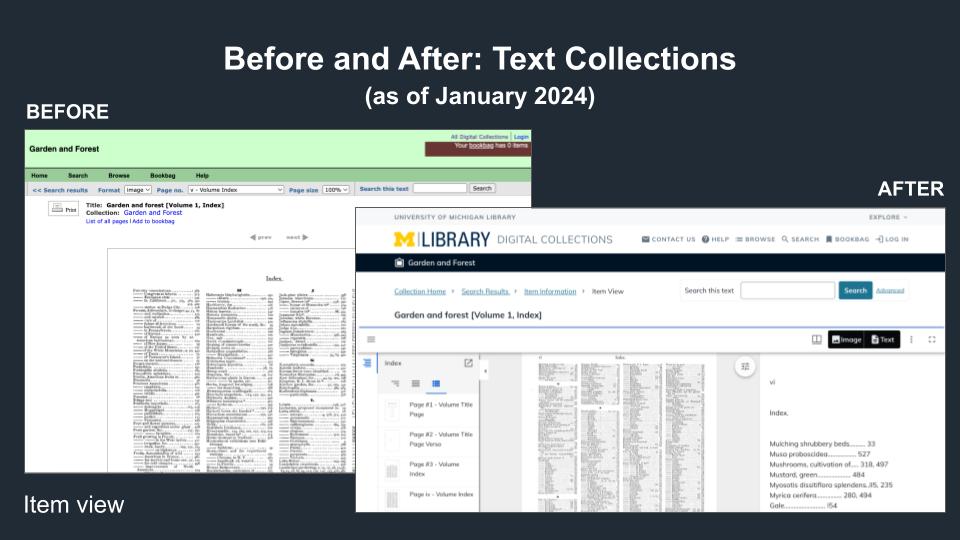
Before and After Text Collections item view
This comparison highlights the original item view for text digital collections (on the left) and the new item view (on the right), which provides the index of pages, page images and OCR/transcription together in the Mirador viewer.
Future plans
We expect to launch the remaining DLXS TextClass digital collections in the uplifted interface by summer, and to follow up with plans for the 20 or so text-based digital collections in the older technical infrastructure.
We’ll then be turning our attention to the technical infrastructure itself, rebuilding that into a more modern system that can be shared across our digital repository services, and allowing for features that we cannot currently offer.
Stay tuned for more blog posts as we continue this work!