by Kat Hagedorn, Christina Powell, Lance Stuchell and John Weise
The one constant in digital preservation over the past couple of decades has been change. Digitization standards have changed as equipment has improved and become more affordable, formats have come and gone, and tools have been developed to help with automated format creation and validation. The progress made on this front has been great, but an issue has emerged for repositories that have been around for a while. How do we reconcile older content with current digitization and preservation standards, even in cases where that content was created with long-term preservation in mind? For us, the challenge inherent in this issue is becoming apparent as we work to migrate digitized texts from our legacy repository to HathiTrust. We knew things like differing digitization and validation standards were going to make this a challenging project, but the true amount of work and time involved did not become apparent until we actually started the work. Migrating older content forward is a community-wide challenge, and we hope that sharing our experience will help others working hard to do the same.
We wish to acknowledge that our interest in writing this post started upon reading the Code{4}Lib Journal article HathiTrust Ingest of Locally Managed Content: A Case Study from the University of Illinois at Urbana-Champaign by Kyle R. Rimkus & Kirk M. Hess. This is an excellent article that we highly recommend. It depicts, in terrific detail, a lot of hard work, the resources required, lessons learned, and the outcomes of the achievement. Our goal with this post is to share our own experience at the University of Michigan, albeit from a broader perspective, with a bit of outwardly expressed enthusiasm for the trials and tribulations that go along with the work. As Information Technology and Preservation librarians at UM, we have been directly involved in establishing HathiTrust’s policies and practices which, as stewards for locally created digital collections, we find both challenging and beneficial to follow.
Some history
In 2007, we began ingesting locally-digitized materials into MBooks - the HathiTrust precursor - to demonstrate its potential as a repository for materials other than those digitized by Google. We started with the History of Math digital collection because it was small enough (less than 1000 volumes), it consisted primarily of monographs, and the materials had been digitized in a single consistent workflow in 2002 and 2003. We ingested this collection using the insights and technology we had at the time and queued our remaining collections for future ingest into HathiTrust.
Following the successful pilot ingest, we made the following selection decisions in choosing collections to be migrated:
- First, collections that met the same general criteria as History of Math, in the belief that grouping by common content types and digitization practices would be the most efficient way to proceed. Focusing on monographs from University Library collections simplified issues involving rights and metadata, and our digitization practices had stabilized to a large extent by 2003.
- Second, older monograph collections (created 1996-2002), including materials from libraries around the state.
- Third, serial collections without special encoding. There can be enumeration and chronology problems in the HathiTrust catalog with serial collections, as many digital items would be attached to a single MARC record.
- Fourth, serial collections that have a more complicated logical structure (journal articles). (1)
We believed that by working from less complex to more complex, we could refine our processes at the beginning of each ingest cycle and allow most of this work to proceed more or less "in the background."
Over the past 2 years, we have ingested the majority of the volumes from 23 of our collections. Two collections of particular interest to content stakeholders have been fully ingested; the rest are still in progress. The number of collections completed remains low because we shifted from a collection-based migration approach to grouping volumes by problem type, which sped progress overall.
Problems we encountered
As ingest has proceeded, we have learned that minimizing variation does not eliminate it, and that more modern tools (e.g., jhove) and stricter validation standards revealed a number of inconsistencies that needed to be addressed before the collections could be ingested. No matter how carefully our digitization specifications for vendors had been written or how well the materials functioned online, we encountered something unexpected with each collection. In the past, we made digitization decisions with the best intentions (and using the latest standards and tools), but the result has not always been compatible with existing requirements.
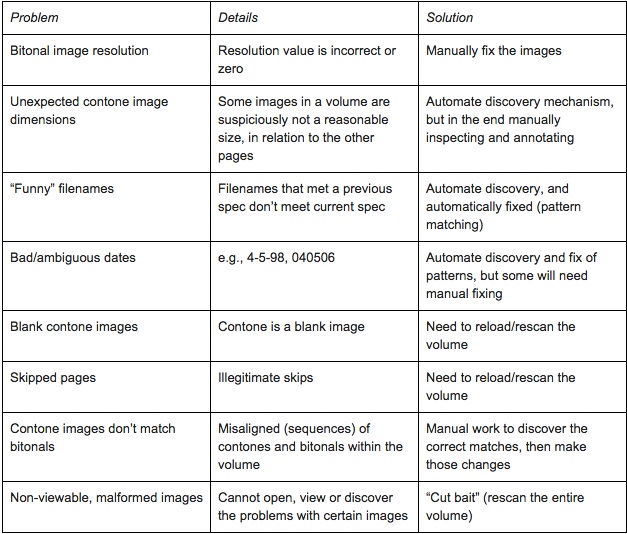
The issues we have encountered have ranged from invalid images (well-formed or not), unexpected contone image dimensions and ambiguous dates, to incorrectly skipped pages, non-matched contones and bitonals, and completely malformed and unviewable images. Some of these issues have been fixable (eg, invalid images) while some have taken much more work or are not fixable (eg, malformed images). The full range of issues is detailed in Lance Stuchell and Kat Hagedorn’s Digital Preservation 2014 presentation, and a selection of them are in the table below.
Preservation and progress
HathiTrust has raised the bar on preservation, and because of it our collections are now more consistently managed and sustainable. Each new issue we’ve encountered has helped to improve our validation and remediation processes for subsequent rounds of ingest, but nothing can adapt to, or even predict, everything we will encounter along the way and many problems can only be solved hands-on.
Strict specifications are good for long-term preservation and expose deficiencies in past practice. However, if the bar is raised so high that it is an obstacle to even trying, it becomes counter-productive. HathiTrust is enforcing conformance to digitization best practices that were arrived at by the digital preservation community, and which we aimed to meet from the outset. When we envisioned future migrations of digitally preserved materials, we had in mind automated processes that would identify bit rot and convert files to modern formats. The future arrived sooner than expected, and migration turns out to involve toiling over a very long a series of difficult puzzles. So let’s remember that we have always done the best we could, and it is no surprise that our best continues to get better. This is progress. This is preservation.
(1) Texts encoded above Level 1 in Best Practices for TEI in Libraries are not yet supported by HathiTrust and thus must be excluded from ingest at this time, limiting complete ingest of collections containing any/all Level 2 and Level 4 texts.