
New Computer refresh cycle tool for the Library
The University of Michigan Library replaces roughly 1/4 of our computers every year. It is a long and complicated process when one considers the number of library staff and the number of computers (both in office and public areas where staff machines are used) involved.
In previous years the library departments across the library have worked with spreadsheets stored on file servers or on Google drive and the need for a more structured and automated tool to handle the refresh cycle became more apparent than ever.
Requirements and building the tool
We started thinking about requirements and needs for this tool. Immediately the need to keep the tool accessible from anywhere became apparent, so we committed to a web-based tool.
The following requirements were also defined:
- Obtain the inventory data from the central desktop support department, in order to populate our database and act on the information we received from them. This was a long and complicated process, and the data needs to be continuously updated so that it reflects reality. As with most new systems that expose previously invisible information, quite a bit of data clean-up was required. There’s still a lot of work to do, but the data quality and accuracy has been greatly improved since we began working with central desktop support to get the inventory cleaned up.
- Allow library staff to be able to see what the status of their assigned machine is, when it’s due to be replaced and in general give a view of what the computing environment looks like in every department within the library.
- Allow designated people in each division to assist their library staff to place the request, or place the request on behalf of the staff. These liaisons are instrumental in communicating with local staff and answering questions about different aspects of the tool and how to use it.
- Involve the Library’s supervisors, senior managers and associate university librarians to review replacement requests coming from staff and designated liaisons across divisions, and approve the requests.
- Compile lists and reports to build carts with central Desktop Support to order the approved equipment.
- Keep it all simple. Dealing with spreadsheets and different ways of describing and requesting equipment is complicated enough. No real surprise there, and the challenge was accepted.
ALIDA
ALIDA stands for Advanced Library Inventory Data Access. It’s named after an adorable little girl. It was one of those things where we came up with the meaning of the letters after we named it. ALIDA’s backend application is based on C# and ASP.NET with a MSSQL Database which also connects to central IT’s Data warehouse, and the front end is a Sinatra/Ruby application that is hosted in the Library’s staff intranet.
For the administrative side of ALIDA, we leveraged SQL Server Reporting Services, a robust reporting tool that delivers reports to the web.
When a library staff member logs on to the site, they see the main menu page with a list of computers that are assigned to them. If they have elevated access (such as liaison or senior manager access) they will see multiple departments (as depicted below).
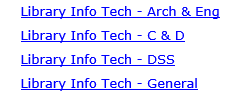
Clicking on any of the available departments, they will see a list of machines that are assigned to them, or all the machines in that department. The view of machines is also able to show them the status of each machine. If it’s in italics and red, the machine is due for replacement.
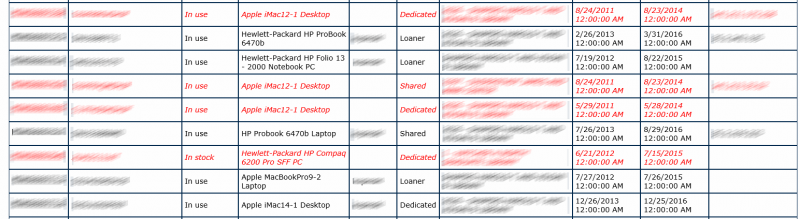
Requesting a replacement is as easy as clicking on the tag for the computer and clicking the button to initiate the request:
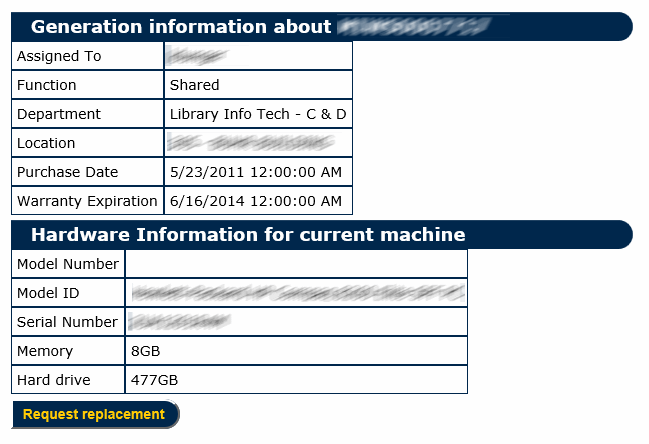
The drop-down menu in the following screen provides a list of the new equipment that is available and it shows the specifications for each option, in case our staff wants to “shop around”:

Once the equipment has been selected, our staff has the ability to customize the equipment such as pick a different keyboard, a different mouse, docking station (if it's a laptop) or a different or additional monitor. After that they click on ‘Submit Replacement request'
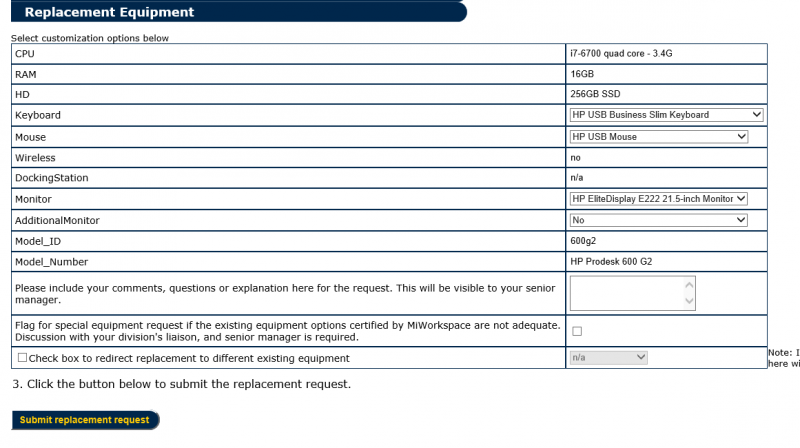
The ability to redirect a replacement to a machine that requires the newer machine more than the machine that is currently up for replacement is possible. This is left up to the discretion of the manager of a specific department.
Once the request is submitted, a queue is generated and the corresponding senior manager and Associate University Librarian of the department will be notified twice a week of pending approvals.

The senior managers may choose to contact the staff or the liaison, or just approve the request if they have no questions.
When the request is approved the state of the machine will change to something like this:

The machine will now be put into a queue to be sent to Central Desktop Support for bulk ordering.
Future work and enhancements.
Tools like ALIDA are almost never done. In the future, we’re planning on adding information about what software is installed on every machine, and provide more views for staff and senior managers to better understand what the state of the computing environment is in their area.
We hope to enable automation that will allow staff to track the status of the replacement machine between the time it was approved and the time it’s scheduled to actually be replaced. We’re working with central desktop support to fit this feature to their process.
Lessons Learned
The first lesson that we learned during the development of this tool is that no matter how good and feature-rich the tool might be, it’s only as useful as the data you put in it. Keeping the data up-to-date can be a major undertaking and the definition of certain details is different for different people.
A good example of the importance of these details is the location of a computer. To a department outside of the Library, the room number and building name might be enough, but to folks who use the equipment on a daily basis it’s a much more personal situation. Finding the compromise between the two can be a bit of a challenge so if you try to build something like this tool, take into account personal/non-canonical descriptions of locations and other details of the equipment you’re trying to keep track of.
Speaking of location of computers and how people define it, another important lesson learned is making sure that the status of computers in the inventory is documented consistently and clearly using standard terms/phrases and procedures. Interfacing with a database on a remote server is only one piece of the puzzle. How different organizations (central desktop support, library, etc) enter, interpret and use the data can vary greatly and there should be clear communication among the parties involved and no assumptions made.
By far though, the most important lesson to learn regarding any tool that aims to automate or formalize any process (not just workstation refresh cycles) is to keep the targeted audience informed and dedicate resources to answer questions and be able to help with making the submission of the data to the tool a successful and easy experience.