This is a version of a talk given at a ‘pop-up workshop’ on the batch editing of metadata sponsored by the Michigan Academic Library Association (MiALA); its original audience was mostly cataloguers, but it is applicable wherever information is stored as text, or can be converted to text. I have been working with structured text for decades, both as a library cataloguer for Jackson Community College and as the head of the Text Creation Unit (TCU) within the University of Michigan Library’s Digital Content and Collections Department. The TCU has been responsible for significant XML-encoded text projects, including the conversion of the Middle English Dictionary to digital form; revision of the MED; and the creation of several full-text corpora that have effectively made much of the history of the English language susceptible to search and analysis, including the Corpus of Middle English and the Early English Books Online corpus (and sibling Text Creation Partnership projects), which have opened up the content of more than 70,000 early printed books.
Editor: This is a lengthier post than most of ours, because of the level of detail it provides, and the actionable steps that it offers for those working on batch editing of metadata. We hope you find it useful!
"If the only tool you have is a hammer, you tend to see every problem as a nail." This was originally meant as a warning: I prefer to see it as empowering advice. Especially if your toolbox also includes a file: use the latter to shape your problem into a nail-shaped excrescence, then hit it. Hammers are what make us human: Roman hammers are hard to distinguish from modern ones, and stone-age hammers are little different. There is something to be said for mature technology, grown familiar through repeated use, and employed with confidence and style. Applied to the manipulation of metadata, my point is that if you can shape your data into text, especially into delimited or structured text, a small box of commonplace old tools -- editors, scripting languages and utilities -- will allow you to do to it almost anything you want.
Consider this record, from the 13,000-record personal book catalog that I’ve been working on since about 1981, and in digital form since the mid-90s. I kept it to 100 records per file in order to make sure that it would fit on 3-½” floppies! and the format is SGML! As metadata, it’s old but not as old as MARC, and it gets the job done.
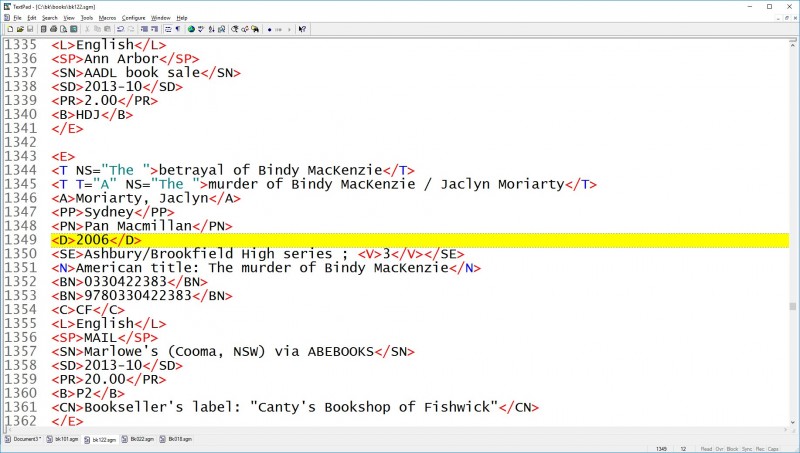
Let’s search and then modify it. To search, I often find it convenient to ‘lineate’ the file -- remove all the newlines within the record, for ease of grepping. Lineating it with Perl takes about 10 seconds, even if I use a plain batch file for file handling, and also illustrates some handy tools.
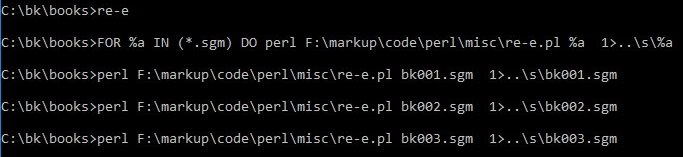
Programmers, avert your gaze -- but everyone else, these little hammers are enough to do about half the data modification you’re likely to need. Here are the batch file and script it runs:
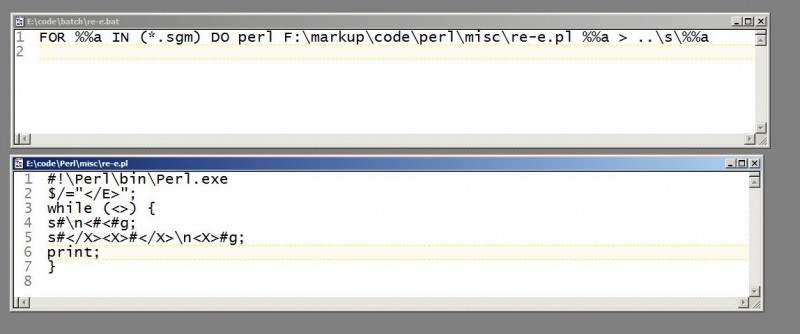
The batch file is a simple “FOR” loop that runs the Perl script on every *.sgm file in the folder. The Perl script itself (at line 2) redefines the newline so that Perl treats each entry (<E>) as if it were a single line; (at line 3) reads each line (i.e entry) in turn; (lines 4 and 5) performs a set of find-and-replace (“substitute”) operations on that line using regular expressions; and (line 6) outputs (“prints”) the results to standard output -- which in the batch file we’ve redirected to a new file of the same name in a sibling folder.
Searching those modified files with a ‘grep’-type find-in-files search (in this case directly within the TextPad editor) can yield fairly sophisticated results, and scales well enough to handle a few hundred files and a few hundred thousand records. You do need to know your data, however.
The first sample search (below) finds records with a T field (title) beginning “Bible”, followed somewhere in the record by an L field (language) beginning with “Greek” and tells me that I apparently own 27 copies of the Bible in Greek. The second similarly tells me that I own nine books by John Buchan that include the word “Nelson” in the name of the publisher (which is reasonable since Buchan was a director of T. Nelson). The third is the most consequential, at least when professional expenses were still tax deductible: it tells me that in 2016 (source date field) I bought 37 books in Middle English (class number ‘LE3’ in my idiosyncratic scheme). Given those records, I could easily pull out the costs (PR = ‘price’ field) and dates (SD = ‘source date’ field), drop them in a spreadsheet and voilá, a tax deduction.
![searching book catalog "Search for: <T[^>]*Bible..."](/sites/default/files/blogs/techtalk/a07_pfs.jpg)
If you can search your data, you can modify it. Most commonly, you’ll want first to extract information of a given kind, sort it, uniq it (remove duplicates), and resolve anomalies. Here I’m searching my book catalog for the string “<K>Tools” (‘tools’ as a keyword or subject heading), and sorting and uniq’ing the results.
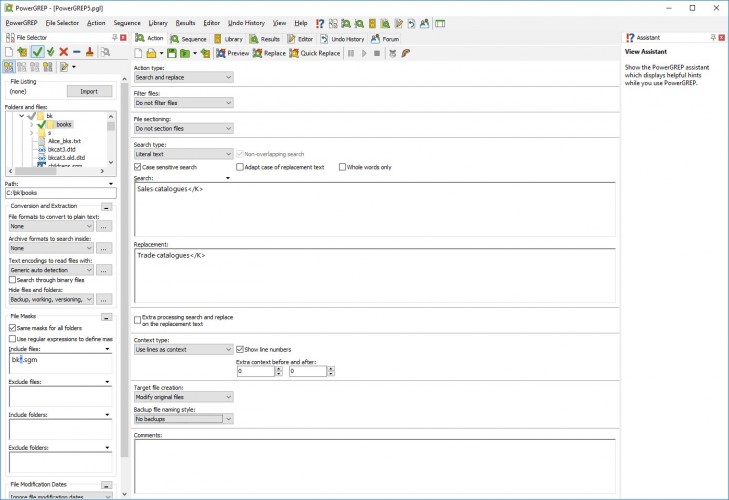
Already, I see some anomalies. “Sales catalogues” and “Trade catalogues” are the same thing; I don’t need two headings. I seem undecided as to whether to capitalize a qualifying term after a comma. And so forth. Turn those anomalies into Perl replacements (here combined with a few others), and you get this:

The script inputs every line (line 7); replaces ‘Sales catalogues’ with ‘Trade catalogues’ when it appears at the end of a keyword field; capitalizes words following “Tools, “; and while I’m at it, makes sure that no nasty Americanized spellings of ‘catalogs’ sneak in. Then it outputs (“print”) the result. Similar results can be achieved with a global replace utility like PowerGrep:
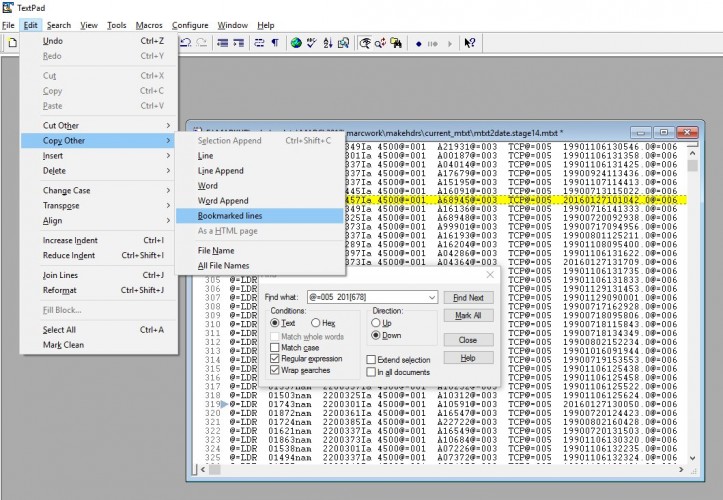
“Find in files” (grepping) is only one way to extract the requisite fields. If you can load the file(s) in a text editor, most editors have a ‘bookmark’ function that allows you to mark lines, then copy and paste them elsewhere. Here I’ve loaded a lineated set of 50,000 MARC records, searched for and marked (see the little blue triangle in the margin) the records that were modified in 2016, 2017, and 2018 (based on a search for “@=005 201[678]” in the 005 field), then copied those particular records to the clipboard for further work.
(Bookmarks are a good way to search for negative results, too -- records that lack a particular feature -- since you can search for those that have it, then invert the bookmarks to leave only those that don’t.)
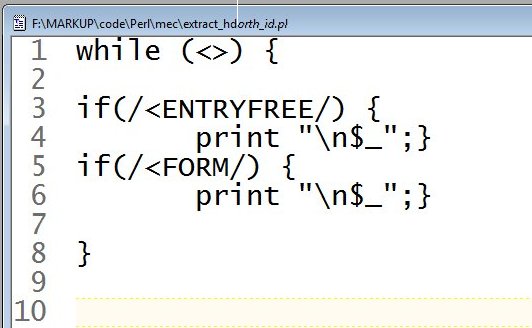
Here, needing to extract two different fields (ENTRYFREE and FORM) from every record in a different set of 50,000+ records, I use yet another way to extract information from records -- the handy Perl ‘match’ (//) operator and ‘current line’ ($_) variable. This script says ‘run through every line; if it matches ENTRYFREE print it; if it matches FORM, print it.’
This approach -- in sum, extracting fields, sorting and uniq’ing them, and pairing them with appropriate replacements in a simple replacement script -- can be carried out to some absurd lengths. In the example below, for example, I extracted, sorted, and uniq’d all 3,000 of the bibliographic abbreviations (“stencils”) in the Middle English Dictionary that lacked an ID linking them to an entry in the dictionary’s Bibliography. Then I provided each of these deficient stencils with a fuller, authorized substitute, turning the whole set of replacements into single script of several thousand lines, meant to be run on all 56,000 of the files that comprise the MED.
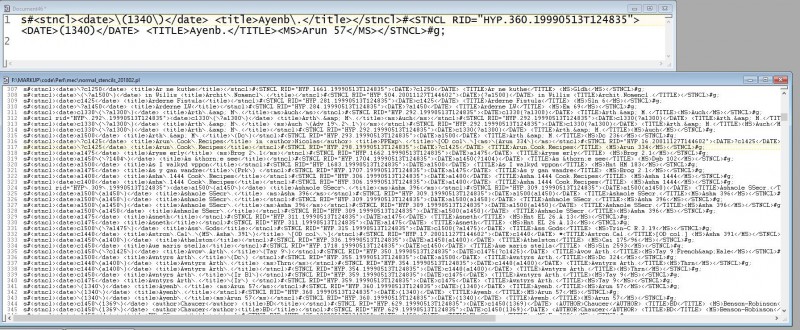
Note that all of these replacements and most of the ones mentioned in this article, assume that one is searching for patterns -- regular expressions. Basic regex language (see below) is easy to acquire and comforting -- essential really -- to have in one’s repertoire.

Now let us consider the common problem of merging information from different record sets, including those in disparate formats, i.e. using information searched for and extracted from one set of records to modify a second set of records.
To record daily work on the EEBO TCP (Text Creation Partnership) transcriptions, my editors used a simple spreadsheet, one for each month’s worth of files.
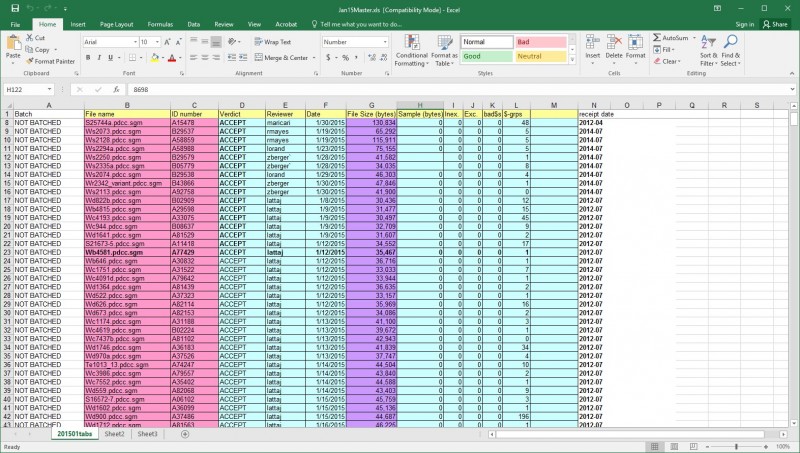
This sheet tells me that these particular files, with these IDs, were proofread and (mostly) ACCEPTed, on a particular date by particular staff members; also that when complete they had a particular file size. It becomes mungible when copied into a tab-delimited text file, like this:
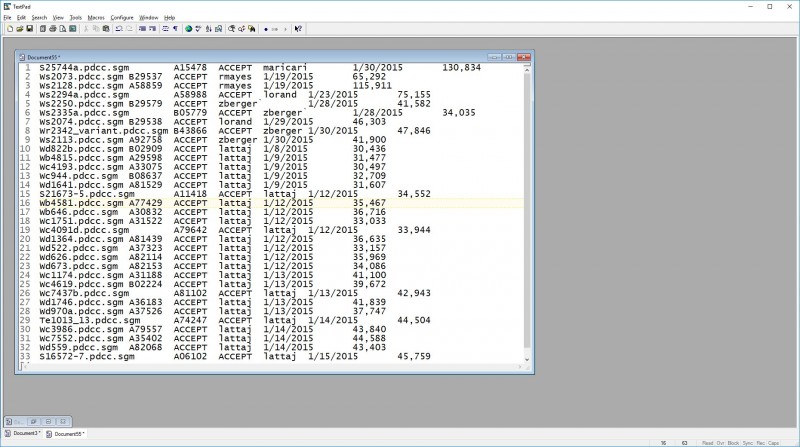
I need to get all of that information into my tracking database, on an entry-by-entry basis. Luckily, both the data and the database are now structured text, so it is easy to open the text file in an editor and turn it into a set of substitutions that search the tracking database for a given ID followed by empty fields, then replace the empty fields with ones populated with the information from the spreadsheet. Brute force, but effective -- and even contains a bit of protection against failure, since if the ID is absent from the database, or if it is present but not followed by empty fields, the script will fail to find a match.
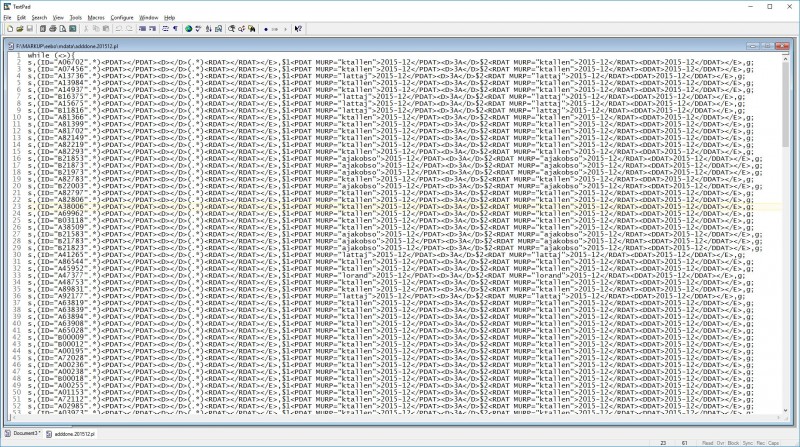
At some point, this search-and-replace brutishness becomes hopelessly inefficient. At that point, consider the hash (or if you’re using Python instead of Perl, the “dictionary”). Here is another actual example of hammer and file at work. The Bibliography to the online Middle English Dictionary contains links to the “New Index of Middle English Verse” (NIMEV); I needed to add links to its rival, the online “Digital Index of Middle English Verse” (DIMEV). How? The tools are all here.
I ‘scraped’ the online site with a batch file of WGET commands to download all the DIMEV records (script at top left); looked at a sample record (top right) and found that thankfully it contained both the NIMEV and DIMEV numbers; wrote a little ‘if match then print’ script in Perl to extract those two numbers from the 5,000 DIMEV files (middle left); ran said script from a batch file that redirected the output to a single file (middle right), producing a set of nimev - dimev pairs (lower right), which could easily be turned into another Perl script (also lower right). In this case, I have preserved the pairs arrangement as a ‘hash’ which maps one value to another in a set of pairs, then invoked that hash in a pair of simple substitutions that look for the NIMEV number, and plug in the DIMEV number from the hash every time they find one. (I will leave you to guess why I first change uppercase INDEX to lowercase index and then back again. Answer at the bottom of this post.**)
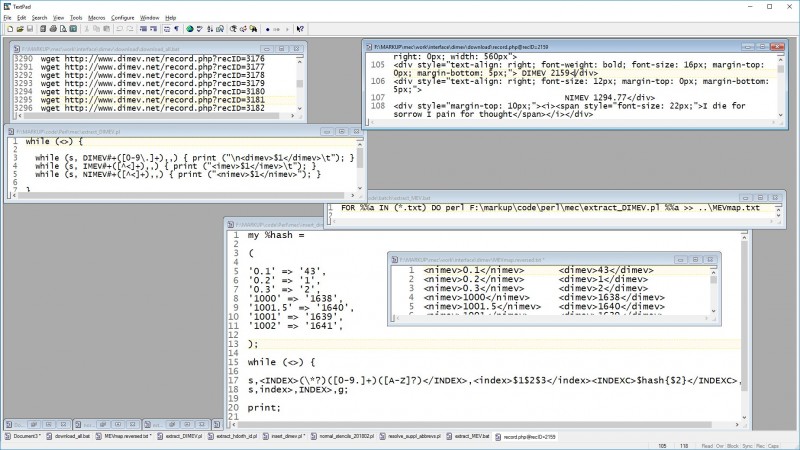
This method, too, can be taken to absurd lengths. When preparing MARC records for the Early English Books (EEBO-TCP) texts, I began with catalog records for the original books and their realization as EEBO images online, introduced a lot of placeholders for book-by-book variables like FILESIZE, IMAGE-COUNT, ONLINE-DATE, IMAGE-SET-ID, and even the whole processing history of each book, from selection to review -- then extracted all that information from our tracking database by extraction methods we’ve already mentioned, turned each set of values into a hash mapping our ID number to the value, included each hash in a script, and ran each script on the 50,000 records.
Here is the MARC record, as text, with placeholders for the information to be added:
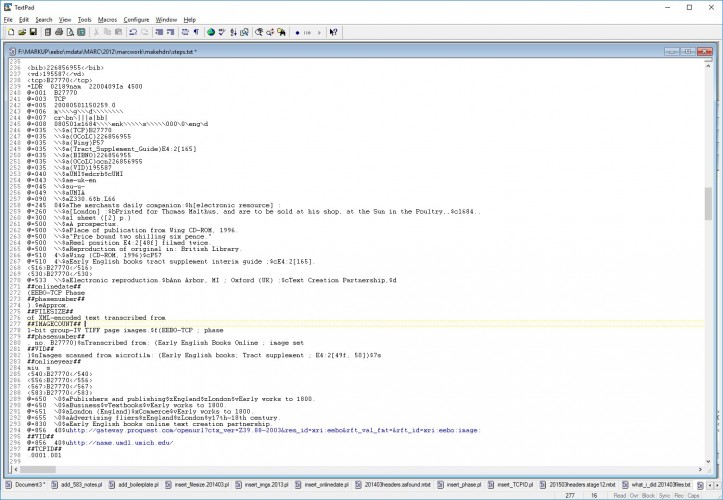
And here are a couple of the hash-based scripts (in truncated form) used to replace the placeholders with real info:
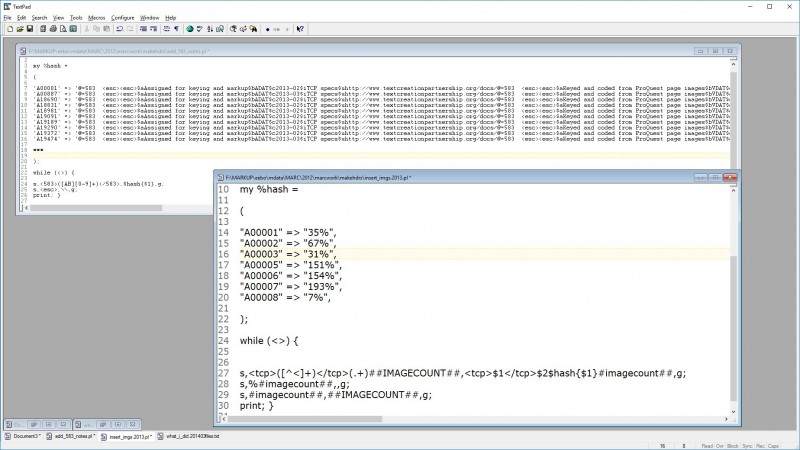
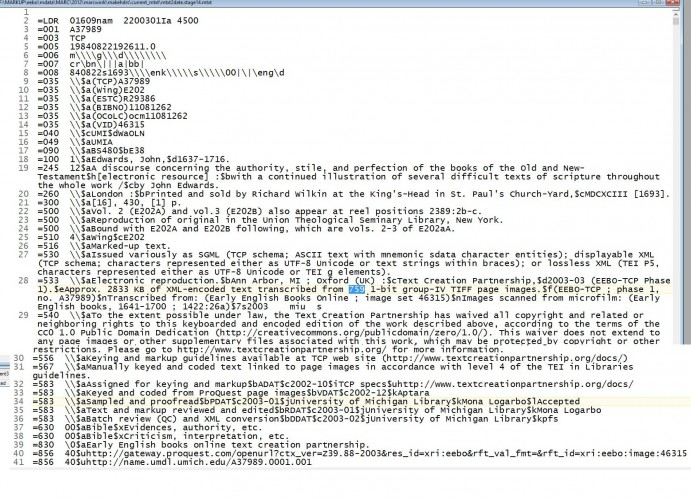
The result was a complete new set of records, populated with all that administrative metadata from the tracking database, all in valid MARC; destined later to be turned into a TEI header for each file. The 516 530 556 540 567 and 830 fields are the same for each record, and so were added by simple substitution scripts (or could have been added in a text editor). The 533 583 and 856 fields are different for each record, and were added by the aforementioned series of hash-based scripts.
Test case
Finally, one last example that uses some of the techniques mentioned so far, and adds one or two: one of the commonest tasks of every cataloguer these days is updating the local load of E-book Central e-book records (formerly Ebrary). I have chosen to receive a full load of current EBC records every month; and I have flagged those that I loaded into our LMS with a distinctive marker that allows me to download them all as a batch, so I can work with both old and new records as complete sets. Those are the only two conditions for this to work. The rest is simple tools. In order:
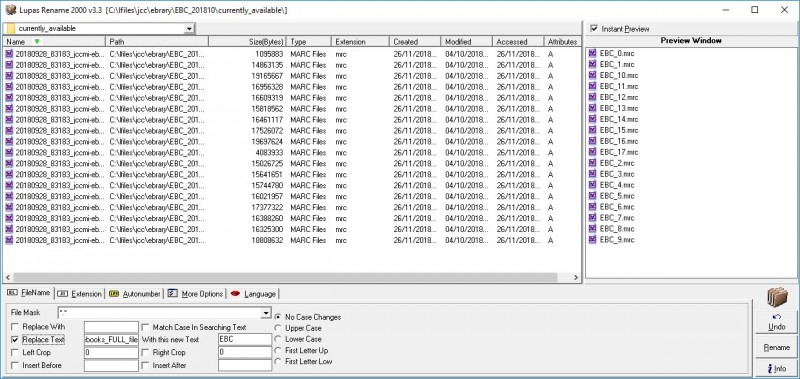
1. I rename the elaborately named current EBC files to simple “EBC_1.mrc” etc. -- to make life simpler, using my favorite file renamer, Lupas Rename (an older version, as usual).
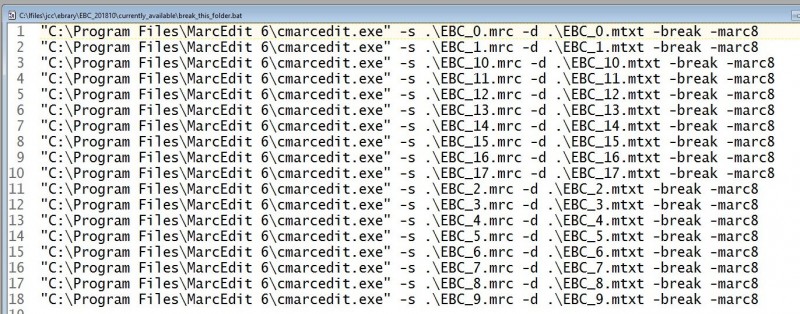
2. In my editor I turn a bare list of marc files into a batch file that runs MarcBreaker, in order to turn the MARC into a text format I can work with, then run that bat file.
3. I ‘grep’ (find in files) the 001 fields from both the new records and the records already loaded in our system, reduce the lists to bare lists of EBC id numbers, uniq them, and sort them -- all within TextPad, though it could also all be done at the command line using the grep, sort, and uniq commands.
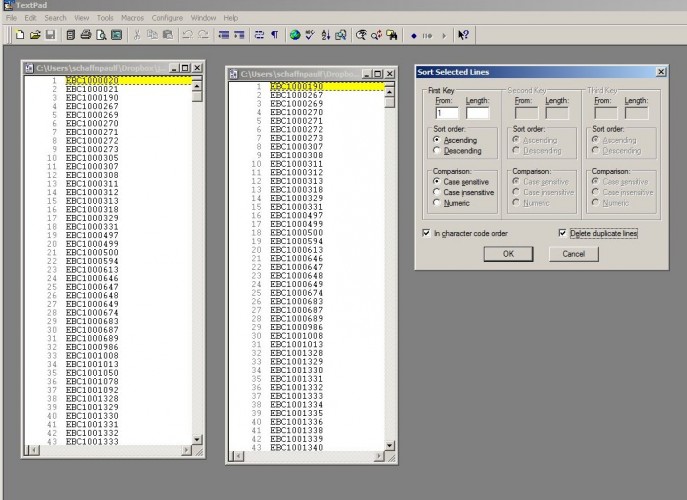
4. I use my single favorite Unix-type utility (in its Windows guise), namely “comm,” to compare the two lists. Comm compares two sorted lists and outputs, at your discretion, the values unique to list 1, the values unique to list 2, and the shared values. In this case, IDs already in our LMS but not in the current records (unique to list 2) should be marked for deletion; those in the current records but not already loaded (unique to list 1) should be marked as “adds” -- and comm produces lists of the two sets of IDs.
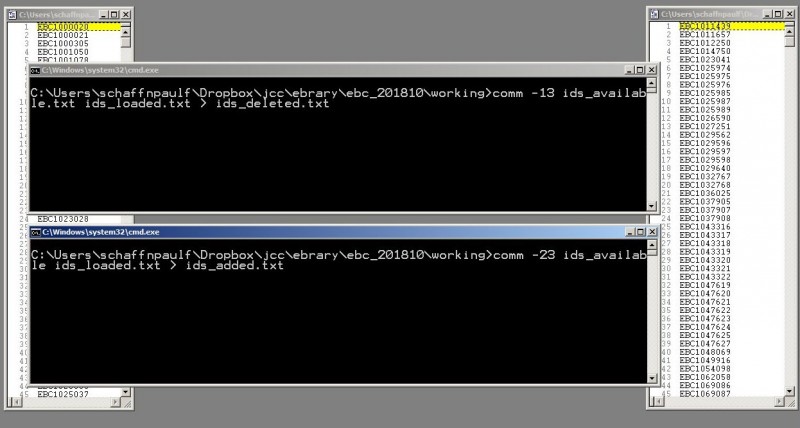
5. The lists of ids-to-be-added and ids-to-be-deleted can each be opened in Textpad and turned into Perl if-match-then-print scripts.
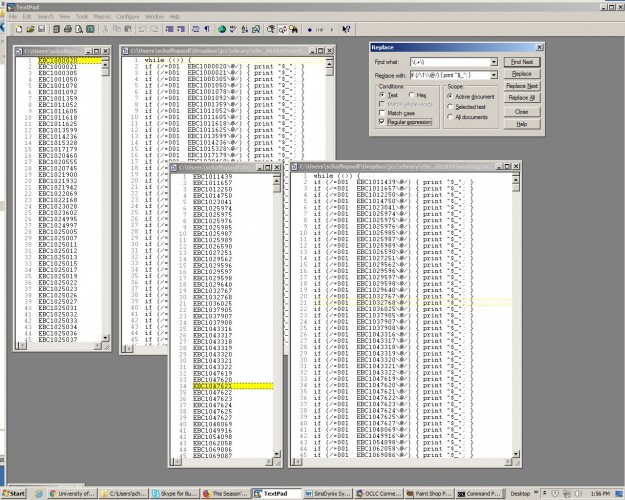
6. The MARC text files themselves are readily lineated, as with my book catalogue, either in the editor or by script, to remove all the newlines within each record and reduce them to one line per record (just replace “\n=” with “@=”).
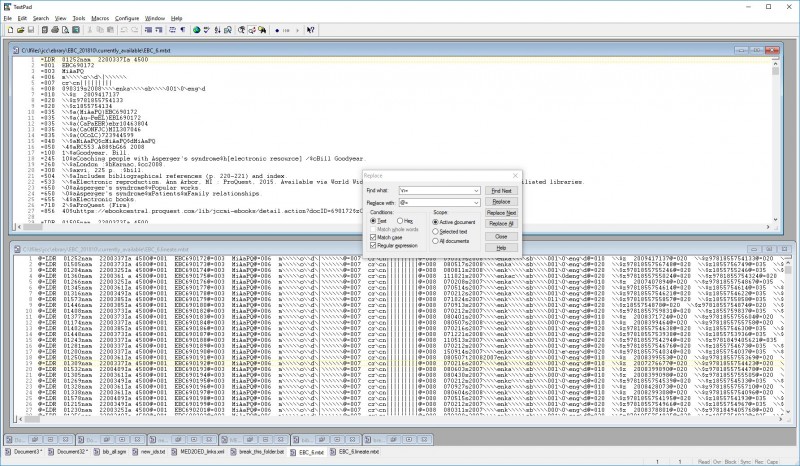
7. The ‘extract deletes’ script and ‘extract adds’ scripts (created in step 5) can then be run on the lineated files, extracting deletes from the file of records already loaded, and extracting adds from the files of records currently available from EBC.
8. Modify those files a little in the editor to make sure that the DELETE bit is set on the deletes and a 949 MARC holdings field is added to the adds. I.e. in the deletes, replace @=LDR ([0-9][0-9][0-9][0-9][0-9])[a-z] with @=LDR $1d. And in the adds, use TextPad’s lovely ‘insert incrementing number’ function (“\i”) to create fake barcodes in a fresh =949 field for all your new ebook items.
9. Turn the lineated add and delete records back into real records by replacing “@=” with “\n=”; turn them back into binary MARC with MarcMaker, and load them into your system. Our system (Symphony) allows records with the delete bit set to automatically delete any records already loaded with the same 001.
That’s it. Takes about an hour.
Lessons
So what are the simple tools that I promised? I’ll list them in the form of lessons.

- Delimited and structured text will yield to your will.
- MarcEdit can be run at the command line.
- Lineating a file (one record per line) allows efficient search and extraction of records.
- Learn basic regex (regular expressions): it takes ten minutes, and you’ll never regret it.
- Reduce complexity by renaming files to something simple
- Extract information from a file, or individual records or fields, using:
- A grep-type search (e.g. find-in-files in an editor)
- Perl by using the if-match-then-print-$_ command
- A search within a text editor + bookmarks
- Tidy, sort, and uniq extracts to find anomalies.
- Use ‘comm’ to find differences between sorted extracts.
- Convert external lists of values into Perl scripts, either
- Brute-force replacements, using the substitute command; or
- Slightly more elegant hash-based replacements.
- Simple Perl, used in this crude fashion, is very simple indeed, confined basically to:
- Using its line-oriented approach, loading each line with a “while (<>) { } “ loop.
- Or redefining the line if you need to.
- Redirecting the output to a file at the command line.
- Avoiding file-handling complexity by running it from a batch file.
- Doing brutish replacements with “s###g;”
- Matching a pattern and printing the containing line with “if (/xxx/ ) { print “$_” }”
Tools mentioned
- MarcEdit (MarcMaker, MarcBreaker tools)
- Lupas Rename
- Text Editors
- PowerGrep
- Perl (Active or Strawberry)
- Windows batch language
- Windows ports of Unix utilities
- Grep
- Sort
- Uniq
- Comm
- Wget
Apply that small toolbox (even omitting a few items) with confidence and the world is your oyster.
**As instructed here, Perl will run every substitution again and again until it cannot find a match, so the replacement needs to be something that doesn't match what it's looking for (changing the case will do): otherwise you get a loop which runs forever.